




Diffusion Model for Generative Image Denoising GitHub: Explore Advanced Techniques and Code
- Image Generators Uncategorized
- November 13, 2024
- No Comments
In the constantly evolving field of artificial intelligence and machine learning, diffusion model for generative image denoising GitHub has emerged as a revolutionary technology. The ability to effectively restore images that are marred by noise has vast implications across industries such as medical imaging, photography, and remote sensing. This blog post delves into various aspects of diffusion models for generative image denoising, exploring their mechanisms, implementation, performance evaluation, and potential applications. As we navigate through this intricate landscape, we will also highlight some valuable resources available on GitHub that can aid in understanding and applying these models.
Introduction to Generative Image Denoising

Generative image denoising is a vital process that enhances image quality by removing unwanted noise while preserving important features and structures. The prevalence of noise in images can result from several factors, including sensor limitations, low light conditions, and transmission errors. If left untreated, noise can severely compromise visual information, making it challenging to interpret images accurately.
The goal of generative image denoising is not just to eliminate noise but to regenerate high-quality images that closely resemble their original, unblemished counterparts. Traditional methods of denoising—such as Gaussian filtering, median filtering, and wavelet transforms—have long been utilized but often fall short in terms of maintaining detail and texture. Enter diffusion models: a novel approach that leverages the principles of stochastic processes to improve the efficacy of image restoration.
The Role of Generative Models in Image Processing
At the heart of generative image denoising lies the concept of generative models. These models learn the underlying distribution of clean images and employ this knowledge to reconstruct images from noisy inputs. By training on large datasets, generative models can capture complex structures, textures, and patterns inherent in the images they attempt to restore.
Diffusion models represent a subset of generative models that focus explicitly on the gradual denoising process. Instead of attempting to generate an image in one fell swoop, they take a stepwise approach, iteratively refining the image by simulating a diffusion-like process. This incremental refinement enables the model to achieve superior results, particularly in cases where noise levels are high or where subtle details need to be preserved.
Impact on Various Domains
The advent of diffusion models for generative image denoising has far-reaching consequences across numerous domains. For instance, in medical imaging, clear, noise-free images are essential for accurate diagnostics and treatment planning. In the world of photography, professional photographers can leverage these models to enhance their work, ensuring that images reflect their intended aesthetic without being compromised by noise artifacts.
Moreover, in fields such as satellite imagery and remote sensing, precise data interpretation hinges upon the quality of the images. Here, diffusion models can facilitate clearer visualizations, enabling better decision-making and analysis. As we traverse further into this blog post, we will uncover the mechanics that make diffusion models such a powerful tool for image denoising.
Diffusion Models: A Powerful Tool for Image Restoration
Diffusion models have garnered attention in recent years due to their innovative approach to generating images and restoring them from noise. Unlike conventional methods that may apply simple filters or heuristics, diffusion models incorporate deep learning techniques and probabilistic reasoning to produce remarkably effective results.
Theoretical Foundations of Diffusion Models
At the core of diffusion models lies the concept of stochastic processes, which describe systems that evolve over time in a probabilistic manner. When applied to image processing, diffusion models begin with random Gaussian noise and gradually transform it into a cleaner image through a series of learned steps. Each step corresponds to a diffusion process that reduces noise while retaining key image features.
This iterative approach has its roots in physics, where diffusion describes how particles spread out over time. In the context of image denoising, this analogy serves to conceptualize how noise can be systematically eliminated in a controlled manner, leading to a sharper, more coherent output.
Benefits Over Traditional Denoising Techniques
One of the most significant advantages of diffusion models is their ability to outperform traditional denoising techniques. Methods like Wiener filtering or total variation regularization may succeed in reducing noise but often result in blurring or loss of fine details. Diffusion models combat these issues by learning the complex distributions of clean images directly from the data.
Additionally, because diffusion models rely on deep neural networks, they can be trained on diverse datasets that encompass a wide variety of image types. This adaptability means that they can generalize well across different domains, leading to impressive performance even in previously unseen scenarios.
Challenges and Limitations
Despite their many strengths, diffusion models are not without challenges. Training these models requires substantial computational resources and large volumes of data to ensure robustness. Moreover, they can be sensitive to hyperparameters, meaning that choosing the right settings is critical for optimal performance.
Furthermore, while diffusion models excel in certain scenarios, they may still struggle with specific types of noise or artifacts that deviate significantly from the training distribution. Researchers continue to explore ways to mitigate these limitations, paving the way for next-generation approaches that will broaden the applicability of diffusion models in denoising tasks.
Understanding the Diffusion Process for Denoising
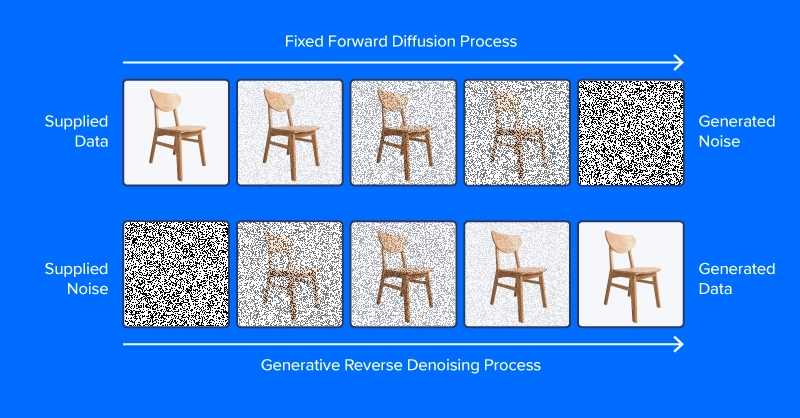
To fully appreciate the capabilities of diffusion models for generative image denoising, it is crucial to understand the underlying diffusion process. This process is characterized by a series of steps, during which noise is gradually removed to reveal the clean image.
Markov Chains and the Denoising Process
Central to the diffusion process is the idea of Markov chains. In this context, a Markov chain describes a sequence of states where the future state depends only on the current state, rather than previous ones. This property allows diffusion models to simulate the transition from a noisy image to a clean one through iterative refinement.
In practice, the initial state is a noisy image, and the model applies a series of transformations based on learned parameters. At each iteration, the model generates a new state that is less noisy than the previous one, gradually converging toward the target clean image.
Forward and Reverse Diffusion Processes
A key aspect of diffusion models is the distinction between the forward and reverse diffusion processes. The forward process involves adding noise to a clean image, effectively transforming it into its corrupted form. Conversely, the reverse process is where the magic happens—it attempts to recover the clean image from the noisy input.
Mathematically, the forward process can be described by a sequence of Gaussian noise additions, which progressively corrupt the image. The reverse process, however, involves employing learned denoising functions that aim to reverse this corruption by predicting the original pixel values based on the noisy observations.
Convergence and Stability
For diffusion models to be effective, they must ensure convergence and stability throughout the denoising process. Convergence refers to the ability of the model to approach the true clean image as the iterations progress, while stability pertains to avoiding oscillations or erratic behaviors during the refinement.
Researchers have developed various techniques to promote stability and convergence in diffusion models, such as using well-defined stopping criteria and adaptive learning rates. These strategies help ensure that the denoising process remains smooth and predictable, ultimately resulting in higher-quality outputs.
Popular GitHub Repositories for Diffusion Model Image Denoising
The open-source community has witnessed an explosion of interest in diffusion models for generative image denoising, reflected in the proliferation of GitHub repositories dedicated to this topic. These repositories provide invaluable resources for researchers and practitioners alike, offering code implementations, pre-trained models, and datasets for experimentation.
Notable Repositories to Explore
Many GitHub repositories serve as excellent starting points for those interested in exploring diffusion models. Some of the most prominent include:
- Denoising Diffusion Probabilistic Models (DDPM): This repository implements the seminal paper on diffusion models and provides a comprehensive framework for training and evaluating various configurations.
- Score-Based Generative Modeling: This repository dives deeper into score-based approaches that leverage Langevin dynamics within the diffusion framework, allowing for enhanced image generation and denoising.
- Diffusion Models for Image Synthesis: Focused on the synthesis aspect, this repository illustrates how diffusion models can be adapted for generating high-fidelity images from scratch, showcasing their versatility beyond denoising.
These repositories typically contain detailed documentation, tutorials, and example notebooks, making it easier for newcomers to get started with diffusion models. They also serve as platforms for collaboration and continuous improvement, fostering innovation within the community.
Community Contributions and Collaboration
The collaborative nature of open-source projects allows researchers and developers to share their findings, improvements, and insights. As the field of diffusion models evolves, GitHub serves as a hub for discussion and experimentation. Users can contribute enhancements, report issues, and propose new features, ultimately driving the advancement of diffusion model techniques.
Engagement with the community can lead to fruitful partnerships, mentorship opportunities, and knowledge-sharing experiences that benefit everyone involved. Additionally, participating in GitHub discussions and projects can spark new ideas and inspire novel approaches to solving challenges within the domain of image denoising.
Gaining Insights from Source Code
Examining the source code provided in GitHub repositories is an excellent way to deepen one’s understanding of diffusion models. By working through implementations, users can familiarize themselves with the architecture, training procedures, and hyperparameter tuning necessary for achieving successful denoising outcomes.
Moreover, reviewing individual contributions can offer insights into different methodologies and perspectives on improving the performance of diffusion models. Engaging with the code not only reinforces theoretical knowledge but also fosters practical skills that can be applied in real-world scenarios.
Implementation Details and Code Walkthrough
Having explored the foundations of diffusion models and their relevance in the realm of generative image denoising, it is time to turn our attention to the practical aspects of implementation. This section will provide a detailed walkthrough of the key components involved in setting up a diffusion model for denoising tasks.
Setting Up Your Environment
Before diving into the code itself, it’s essential to establish a proper programming environment. Most diffusion model implementations are built using popular libraries such as PyTorch or TensorFlow, both of which support GPU acceleration for faster training times.
To set up your environment, you will first need to install the necessary libraries. For instance, if you’re using PyTorch, you can follow the installation guidelines found on the official website. Additionally, consider creating a virtual environment to keep your dependencies organized.
Once your environment is ready, cloning a relevant GitHub repository will provide a solid foundation for your project. Be sure to check the README file for any additional setup instructions or prerequisites.
Key Components of the Codebase
Within the chosen repository, you’ll likely find multiple components that are crucial for implementing the diffusion model. These typically include:
- Data Loading: This module handles loading and preprocessing the dataset that will be used for training. Datasets may include clean images alongside their corresponding noisy versions for supervised learning.
- Model Architecture: The model architecture defines the structure of the diffusion network. It typically comprises convolutional layers, normalization layers, and activation functions tailored for image processing tasks.
- Training Loop: The training loop manages the iterative process of updating model weights based on loss calculations. This portion of the code includes optimizers, learning rate schedules, and logging mechanisms for tracking progress.
- Evaluation Metrics: After training, evaluating the model’s performance is essential. The evaluation module may calculate metrics such as PSNR (Peak Signal-to-Noise Ratio) or SSIM (Structural Similarity Index) to quantify the effectiveness of the denoising process.
Sample Code Walkthrough
To illustrate how these components fit together, here’s a simplified example of what the code for a basic diffusion model implementation might look like:
import torch
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from my_diffusion_model import DiffusionModel
# Load dataset
transform = transforms.Compose([transforms.ToTensor()])
dataset = MyImageDataset(transform=transform)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# Initialize model
model = DiffusionModel()
# Training loop
for epoch in range(num_epochs):
for batch in dataloader:
noisy_images = batch['noisy']
clean_images = batch['clean']
# Forward pass
outputs = model(noisy_images)
loss = compute_loss(outputs, clean_images)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % log_interval == 0:
print(f"Epoch [")This example highlights the fundamental structure of a diffusion model training script, where data is loaded, the model is initialized, and the training loop updates weights based on loss calculations. While this is just a fraction of what goes into an actual implementation, it captures the essence of integrating the various components required for a functional diffusion model.
Training Your Own Diffusion Model for Generative Image Denoising GitHub
Equipped with an understanding of the implementation details, you may now wish to train your own diffusion model for image denoising. This section will guide you through the training process, outlining key considerations and best practices along the way.
Choosing the Right Dataset
The success of your diffusion model heavily depends on the quality and diversity of the dataset used for training. Selecting an appropriate dataset should consider factors such as:
- Image Quality: High-resolution images are preferred since they allow for more accurate feature extraction. Datasets that contain a variety of scenes—such as landscapes, portraits, and urban environments—will enable the model to generalize better.
- Noise Types: It’s essential to include a range of noise types in your dataset. Consider augmenting clean images with synthetic noise generated using common noise models (e.g., Gaussian, Poisson, or salt-and-pepper noise). This strategy can improve the model’s robustness against different noise scenarios.
- Size of the Dataset: Having a larger dataset generally leads to improved performance, as it provides the model with more examples to learn from. However, keep in mind that larger datasets may require more computational resources for training.
Configuring Hyperparameters
Properly configuring hyperparameters is vital for optimizing your diffusion model’s performance. Key hyperparameters to consider include:
- Learning Rate: This parameter dictates the size of weight updates during training. A learning rate that is too high can lead to divergence, while one that is too low can slow down convergence. Experimentation is crucial to find the optimal learning rate for your specific model and dataset.
- Batch Size: The batch size influences memory consumption and training speed. Larger batch sizes can improve convergence but may require additional GPU memory. Smaller batch sizes often allow for better generalization at the cost of training speed.
- Number of Steps: The number of diffusion steps determines how thoroughly the model refines the noisy input. More steps can lead to better denoising performance, but they also increase training time and complexity.
Monitoring Training Progress
As you train your diffusion model, monitoring its performance at regular intervals is essential. Tools such as TensorBoard can facilitate visualization of key metrics, including loss curves and sample outputs. Keeping track of these indicators allows you to make informed decisions regarding hyperparameter adjustments or early stopping if the model begins to overfit.
Regularly saving model checkpoints can also be a strategic move; this practice ensures that you do not lose progress in the event of unexpected interruptions. Experiment with various architectures, alterations, and training techniques to arrive at the most effective configuration for your specific application.
Evaluating Denoising Performance and Metrics
Once training is complete, evaluating the performance of your diffusion model is a critical step in determining its effectiveness in denoising images. This section outlines the various metrics commonly used to assess denoising performance and offers insights into interpreting these results.
Common Evaluation Metrics
Several standard metrics exist for quantifying the quality of denoised images. Among the most widely used are:
- PSNR (Peak Signal-to-Noise Ratio): PSNR measures the ratio between the maximum possible power of a signal and the power of corrupting noise. A higher PSNR value indicates better image quality and less distortion, making it a popular choice for evaluating denoising algorithms.
- SSIM (Structural Similarity Index): SSIM evaluates the structural similarity between two images, taking into account luminance, contrast, and structural information. An SSIM score closer to 1 suggests that the denoised image maintains much of the original image’s integrity.
- LPIPS (Learned Perceptual Image Patch Similarity): LPIPS is a perceptually-driven metric that compares images using deep features rather than pixel-wise differences. This metric focuses on human perception, providing a more nuanced assessment of image quality.
Visual Inspection
While quantitative metrics are essential for evaluation, visual inspection remains one of the most effective methods for assessing image quality. Examining samples of denoised images side by side with their original counterparts allows for a qualitative understanding of how well the model performs.
During visual inspection, pay attention to aspects such as:
- Detail Preservation: Evaluate whether fine details, textures, and edges are maintained in the denoised image.
- Artifact Reduction: Observe if the model successfully removes random noise without introducing artifacts or distortions.
- Color Fidelity: Ensure that colors in the denoised image remain true to the original, avoiding color shifts or strange hues.
Comparing Against Baselines
To gauge the effectiveness of your diffusion model, compare its denoising performance against baseline methods. Implementing traditional denoising techniques—such as median filtering or non-local means—and evaluating their performance alongside your model can yield valuable insights into where diffusion models excel or where they may need improvement.
Incorporating statistical analysis of the results can further enhance your evaluation. Consider conducting hypothesis testing to determine if the performance improvements achieved by your diffusion model are statistically significant when compared to baselines.
Applications of Diffusion Model Image Denoising
The versatility of diffusion models for generative image denoising paves the way for a myriad of real-world applications across various domains. This section explores some notable applications where diffusion models can enhance image quality and usability.
Medical Imaging
In the field of medical imaging, high-quality, noise-free images are crucial for accurate diagnosis and treatment planning. Diffusion models can significantly improve the clarity of MRI or CT scans, aiding radiologists in detecting abnormalities that may otherwise go unnoticed.
By reducing noise without sacrificing essential details, diffusion models empower healthcare professionals to make more informed decisions. Furthermore, advancements in telemedicine and remote diagnostics can benefit greatly from enhanced imaging capabilities, ensuring that patients receive timely and accurate assessments.
Photography and Video Editing
Professional photographers and video editors often grapple with noisy images captured in challenging lighting conditions. Using diffusion models for denoising allows them to salvage otherwise unusable shots, enhancing the overall quality of their work.
Moreover, the ease of integration with existing editing software makes diffusion models an attractive option for creatives looking to streamline their workflows. The ability to maintain detail and texture while reducing noise aligns perfectly with the artistic goals of photographers seeking to create visually stunning imagery.
Remote Sensing and Satellite Imagery
In the realm of remote sensing and satellite imagery, the need for precise, high-resolution images cannot be overstated. Noise in satellite images can hinder data interpretation, affecting environmental monitoring, land-use classification, and disaster response.
Employing diffusion models to denoise satellite imagery can lead to clearer visuals that facilitate better decision-making and data analysis. Enhanced image quality enables researchers, policymakers, and disaster response teams to make informed choices based on accurate and reliable information.
Gaming and Virtual Reality
As gaming and virtual reality technologies continue to advance, the demand for high-quality graphics becomes increasingly pronounced. Diffusion models have the potential to improve in-game visuals by effectively denoising assets, ensuring immersive experiences without distracting artifacts.
By applying diffusion models to real-time rendering scenarios, game developers can elevate the overall experience for players, leading to more captivating and realistic environments. This application reflects the broader trend of incorporating AI-driven solutions into creative industries.
Future Directions and Research Opportunities
The emergence of diffusion models for generative image denoising marks a significant turning point in image processing techniques. However, there are still numerous avenues for exploration and research that can further refine and expand upon these methodologies.
Enhancements to Model Architectures
Continued research into novel architectures can pave the way for more sophisticated and efficient diffusion models. Exploring hybrid designs that integrate principles from other generative models—such as GANs (Generative Adversarial Networks)—could yield promising results.
Investigating lightweight architectures that retain performance while reducing computational overhead is another research direction worth pursuing. Such advancements would facilitate the deployment of diffusion models in resource-constrained environments, further widening their accessibility.
Addressing Limitations and Challenges
Identifying and addressing the limitations of current diffusion models represents a vital area for ongoing research. Strategies for improving robustness against various types of noise, mitigating sensitivity to hyperparameters, and minimizing training requirements will be crucial for advancing the field.
Developing adaptive frameworks that dynamically adjust parameters during training may offer a path to greater efficiency and effectiveness. This area of research presents exciting opportunities for collaboration between engineers, computer scientists, and domain experts.
Interdisciplinary Applications
Beyond traditional image denoising tasks, diffusion models hold promise for interdisciplinary applications that span multiple domains. Investigating how diffusion models can be employed in fields such as art restoration, cybersecurity, or even natural language processing could yield innovative solutions to unique challenges.
Interdisciplinary collaborations can facilitate knowledge exchange, bridging gaps between different research areas and inspiring new perspectives on common problems. Embracing shared methodologies can lead to breakthroughs that push the boundaries of what is possible with diffusion models.
Conclusion: The Potential of Diffusion Models for Image Denoising
The journey into the world of diffusion models for generative image denoising reveals the transformative potential of this technology in enhancing image quality across diverse applications. With their iterative refinement process, diffusion models have proven to be a formidable tool for tackling the challenges associated with noise in images.
From medical imaging to photography and remote sensing, the benefits of adopting diffusion models are evident, as they empower practitioners to make informed decisions based on clearer visuals. As research in this area continues to thrive, the possibilities for improving model architectures, addressing limitations, and exploring interdisciplinary applications remain vast.
In summary, the future of diffusion models for generative image denoising is bright, offering exciting prospects for innovation and progress. By harnessing the power of AI and machine learning, we can unlock new capabilities and push the boundaries of image restoration, shaping a future where clarity prevails over chaos.
Looking to learn more? Dive into our related article for in-depth insights into the Best Tools For Image Generation. Plus, discover more in our latest blog post on generate an image of ichigo kurosaki from bleach. Keep exploring with us!
Related Tools:
Image Generation Tools
Video Generators
Productivity Tools
Design Generation Tools
Music Generation Tools