




Generate Image Detection Data: Boost AI Model Accuracy
- Image Generators
- December 2, 2024
- No Comments
In the age of artificial intelligence and machine learning, the demand for high-quality image detection data has surged dramatically. Image detection plays a crucial role in various applications, from autonomous vehicles to facial recognition systems. As a result, generating reliable and accurate image detection data is essential for training models that can perform these complex tasks effectively. This comprehensive guide aims to elucidate the importance of high-quality image detection data, explore methods for generating it, discuss data augmentation techniques, and provide insights into tools, best practices, challenges, ethical considerations, and future trends in this field.
The Importance of High-Quality Image Detection Data
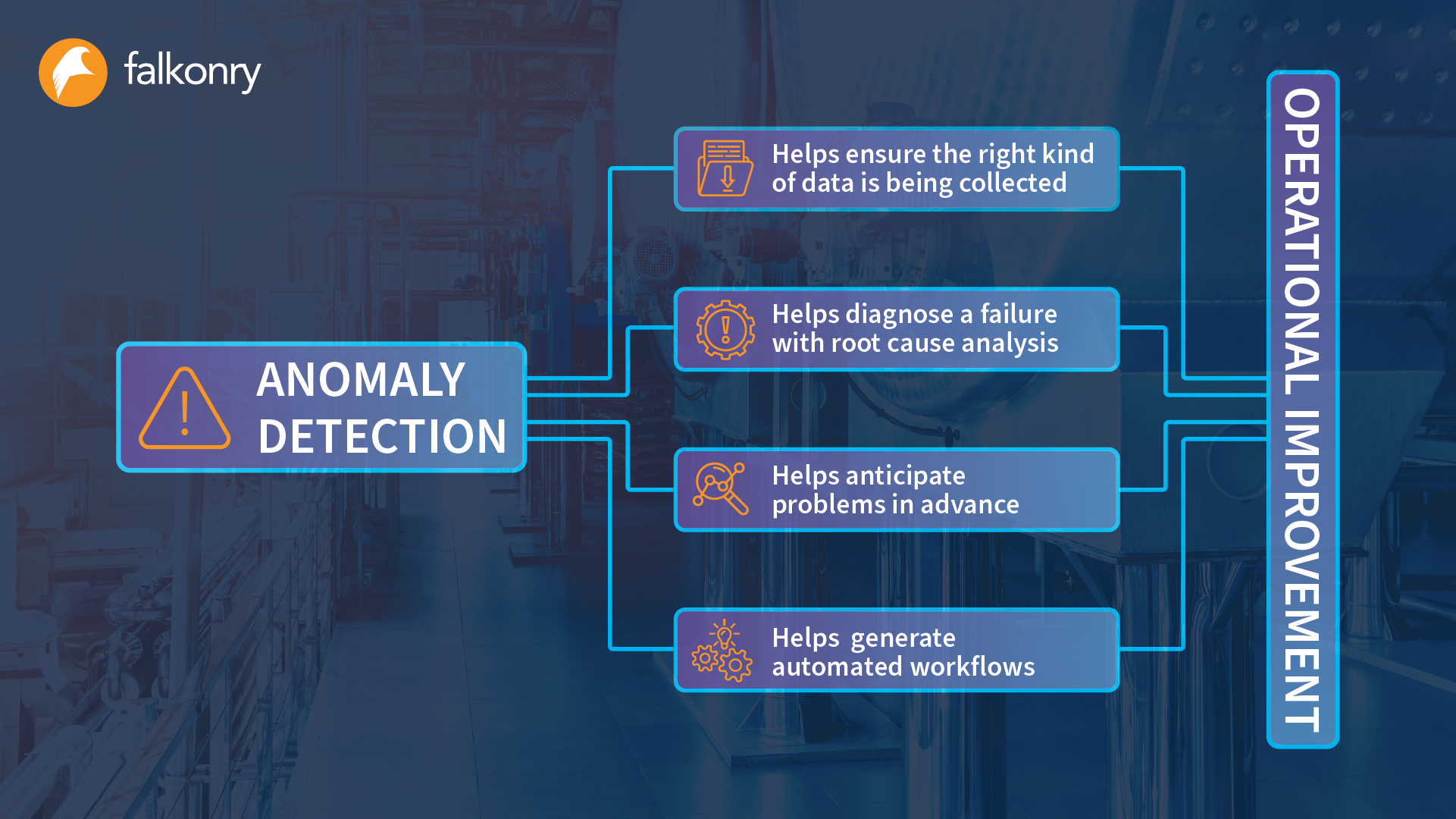
The quality of image detection data directly impacts the performance of machine learning models. High-quality data results in more accurate predictions, fewer errors, and ultimately better user experiences. It thus becomes critical to understand why the generation of image detection data cannot be overlooked.
Enhancing Model Accuracy
One of the primary benefits of high-quality image detection data is its direct effect on model accuracy. Models trained with well-curated datasets tend to generalize better, minimizing overfitting and improving their ability to identify and classify objects in new images.
When generating image detection data, investing time and resources into ensuring clarity, precision, and relevance will pay off in the long run. For example, models like YOLO (You Only Look Once) or SSD (Single Shot Detector) require vast amounts of annotated images to learn effectively. The clearer the annotations and the more representative the dataset, the better the model performs in real-world scenarios.
Increasing Robustness Against Variations
High-quality image detection data equips models to handle variations that occur in real-world applications. These variations could include differences in lighting, background clutter, occlusions, and even perspective shifts. When models are exposed to diverse yet relevant data during training, they become robust against such variations.
For instance, consider an object detection model tasked with identifying pedestrians. If the dataset includes images taken under different weather conditions—sunny, rainy, foggy—and from various angles, the model will be better equipped to detect pedestrians regardless of environmental factors. Thus, high-quality data serves as the foundation for building resilient AI systems.
Facilitating Faster Development Cycles
Another significant advantage of high-quality image detection data is its ability to facilitate faster development cycles. A well-curated dataset reduces the need for extensive iterations during model training. In turn, this leads to shorter timelines for project completion.
Furthermore, when developers spend less time cleaning and refining data, they can focus on enhancing algorithms and fine-tuning model parameters. A streamlined workflow promotes innovation and agility, allowing teams to roll out technology that meets the demands of an evolving market.
Methods to Generate Image Detection Data
The process of generating image detection data encompasses several methodologies, each with its own strengths and weaknesses. Below are some widely adopted methods in the industry.
Manual Annotation Techniques
Manual annotation techniques involve human annotators labeling images for specific objects or features. While this method can be time-consuming, it’s often regarded as one of the most reliable ways to generate high-quality datasets.
Human annotators can employ various strategies, including bounding box annotation, polygonal segmentation, and landmarking. Each technique allows for different levels of detail and precision, ensuring that models receive the appropriate context for learning.
However, manual annotation can also lead to inconsistencies if not carefully managed. Annotators may interpret images differently, leading to variations in how data is labeled, which can ultimately affect model performance. Therefore, proper training and guidelines for annotators are fundamental to achieving consistency across datasets.
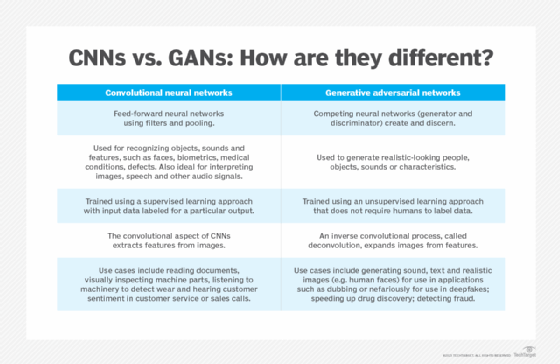
Synthetic Data Generation
Synthetic data generation is a fascinating approach that leverages computer graphics to create new images. By utilizing techniques such as generative adversarial networks (GANs), developers can produce realistic images that mimic real-world scenarios without the need for extensive photography.
These synthetic datasets can be particularly useful when real-world data is scarce or difficult to obtain. For example, in situations where privacy concerns limit access to personal images, synthetic data comes to the rescue, providing ample training material while maintaining compliance with regulations.
One notable advantage of synthetic data is the ability to control variables during the generation process. Developers can tweak aspects such as lighting, angle, and even object placement, creating a varied dataset that prepares models for diverse conditions. Despite its benefits, synthetic data must still be validated against real-world data to ensure it translates effectively in practical applications.
Utilizing Pre-existing Datasets
In many cases, developers can take advantage of pre-existing datasets compiled by researchers and organizations. Popular datasets such as COCO (Common Objects in Context) and Pascal VOC provide a wealth of labeled images across various categories, making them valuable resources for training image detection models.
Leveraging these datasets can significantly speed up the development process, especially for smaller projects that may lack the budget for extensive data collection and annotation efforts. However, it’s essential to ensure compatibility between the chosen dataset and the specific requirements of the model being trained.
While utilizing existing datasets can shorten development timelines, caution should be exercised to avoid model bias due to data imbalance. Researchers must assess the diversity of the dataset and ensure it aligns with the demographic and contextual factors relevant to the intended application.
Data Augmentation Techniques for Image Detection
Data augmentation is a pivotal strategy in generating image detection data, enhancing existing datasets by artificially increasing their size and variability. Implementing effective data augmentation techniques ensures your models remain robust and versatile while receiving adequate exposure to diverse scenarios.
Geometric Transformations
Geometric transformations are among the most common data augmentation techniques. These transformations include operations like flipping, rotating, scaling, and cropping images. By applying these changes, developers can create numerous variations of existing images, all while preserving the original labels.
For example, if you have a dataset containing images of cars, flipping the images horizontally doubles the dataset’s size while introducing variations that allow the model to learn from different perspectives. Similarly, scaling and cropping enable the model to recognize vehicles at various distances, enriching its understanding and improving its accuracy.
However, care must be taken to ensure that geometric transformations do not introduce unrealistic scenarios. Occasionally, extreme rotations or flips may render the images implausible, potentially confusing the model during training. Finding a balance between variability and realism is crucial to optimizing model performance.
Color Space Adjustments
Color space adjustments constitute another effective form of data augmentation. These techniques involve modifying the brightness, contrast, saturation, and hue of existing images. By applying subtle color changes, you create variations that enhance the model’s ability to recognize objects under different lighting conditions.
For instance, increasing brightness can simulate outdoor scenes during different times of the day, while adjusting hue can help expose the model to color variations that might arise due to weather changes. Since real-world images may vary significantly in terms of color, employing these techniques adds valuable robustness to the training set.
Moreover, the impact of color space adjustments extends beyond appearance. They also influence the feature extraction process within models. Diverse color inputs enrich the model’s overall understanding and improve its capacity to generalize across unseen data.
Noise Injection
Adding noise to images is a powerful technique to create resilience in models. Noise injection involves overlaying random pixel values onto images, simulating distortion or interference that could occur in real-world scenarios.
This augmentation helps models to become less sensitive to minor fluctuations in input data, thereby enhancing their detection capabilities in challenging environments. Introducing Gaussian noise, speckle noise, or salt-and-pepper noise can simulate disturbances commonly encountered in practical applications.
However, caution is advised to prevent overloading the model with excessive noise. It’s crucial to strike a balance between making the data more challenging and maintaining the integrity of the original content. Too much noise can confuse the model, leading to increased error rates during detection.
Tools and Platforms for Image Detection Data Generation
Numerous tools and platforms exist to assist developers in generating high-quality image detection data. Understanding the available options enables teams to make informed decisions tailored to their specific needs.
Labeling Tools
Labeling tools serve as essential assets in the image data generation process. These tools streamline the manual annotation of images, allowing users to efficiently label objects and features for their datasets. Popular labeling tools include VGG Image Annotator, RectLabel, and Labelbox.
These platforms offer user-friendly interfaces designed to simplify the annotation process. Users can draw bounding boxes, polygons, and keypoints, facilitating accurate labeling across multiple images. Some tools even support collaborative efforts, enabling multiple annotators to work on the same dataset simultaneously.
Selecting the right labeling tool hinges on the complexity of the project, the skill level of the annotators, and the required output formats for subsequent model training. Investing time in evaluating different labeling tools can lead to improved productivity and higher-quality annotated datasets.
Data Augmentation Libraries
Various libraries are available to simplify data augmentation processes. OpenCV, Albumentations, and imgaug are popular choices, offering a range of techniques to enhance image datasets.
Developers can harness these libraries to automate the augmentation process for large datasets, saving time and reducing human error. Many libraries also provide a plethora of techniques, including geometric transformations, color adjustments, and noise injections, enabling developers to experiment easily and find optimal combinations that suit their specific needs.
Ease of integration with existing workflows is another vital consideration when selecting a data augmentation library. Compatibility with prominent deep learning frameworks such as TensorFlow or PyTorch ensures seamless incorporation into model training pipelines.
Cloud-Based Solutions
As cloud computing becomes increasingly prevalent, numerous cloud-based solutions have emerged for generating image detection data. Services like Amazon SageMaker and Google Cloud AutoML offer integrated environments for data labeling, augmentation, and model training.
These platforms allow developers to access scalable computing resources while streamlining the entire data generation process. By leveraging cloud-based solutions, organizations can benefit from reduced infrastructure costs and accelerated development timelines.
Cloud-based services also promote collaboration among distributed teams, enabling members to work cohesively regardless of physical location. However, careful attention must be paid to security and compliance standards when utilizing cloud solutions, particularly in industries with stringent data protection regulations.
Best Practices for Annotating Image Detection Data
Effective annotation practices can significantly enhance the quality and utility of generated image detection data. Here are some best practices to consider.
Establish Clear Guidelines and Standards
Creating detailed guidelines and standards for annotation is vital in ensuring consistency across the dataset. These guidelines should outline specific criteria for labeling objects, acceptable tolerances for variations, and examples of both correct and incorrect annotations.
Having clear standards empowers annotators to make informed decisions while mitigating discrepancies between individual interpretations. Regularly reviewing and updating these guidelines based on feedback and emerging trends ensures they remain relevant and effective.
Utilize Multiple Annotators for Quality Assurance
To improve reliability, it’s beneficial to engage multiple annotators for the same set of images. This practice allows for cross-verification of the labeled data, minimizing the chances of bias and errors.
Through this approach, any inconsistencies can be identified and addressed before the data proceeds to model training. Additionally, fostering a collaborative culture among annotators encourages knowledge sharing and collective improvement.
Incorporate Feedback Loops
Establishing feedback loops enhances the annotation process by encouraging continuous improvement. Providing annotators with constructive feedback on their work allows them to refine their skills, ultimately leading to higher-quality annotations.
Regular meetings and check-ins can facilitate open communication, giving annotators opportunities to share challenges, ask questions, and collaboratively brainstorm solutions. Continuous training sessions will further equip annotators with the latest tools and techniques, enhancing their efficiency and consistency.
Challenges in Generating Image Detection Data
Despite the advancements in image detection data generation, several challenges persist. Recognizing these challenges enables developers to adopt proactive strategies to mitigate their impact on model performance.
Data Imbalance and Bias
Data imbalance and bias are two pervasive challenges in image detection data generation. An overrepresentation of certain classes may lead to biased models that perform poorly on underrepresented categories.
For instance, a pedestrian detection model trained predominantly on images of adults may struggle to recognize children or individuals with mobility aids. To combat this issue, developers need to ensure that the dataset reflects the diversity present in real-world scenarios, incorporating images from various demographics, backgrounds, and contexts.
Strategies for addressing data imbalance include augmenting underrepresented classes and using techniques such as oversampling or undersampling to equalize distributions. Additionally, actively seeking out diverse sources of images can contribute to more equitable datasets.
Annotation Scalability
The scalability of annotation efforts poses a challenge, especially for extensive datasets. Manual annotation is labor-intensive and may not keep pace with the rapid growth of data needs in many projects.
To address this issue, organizations can leverage automation tools, crowdsourcing platforms, or semi-automated annotation systems. Crowdsourcing provides access to a broader pool of annotators, while automated tools can reduce the manual workload, allowing teams to scale their efforts more effectively.
However, while automation can expedite the process, it should be approached cautiously. Automated annotations may lack the nuance provided by human insight, necessitating careful review and validation.
Keeping Up with Rapid Technological Advancements
Rapid technological advancements in fields like computer vision and machine learning create both opportunities and challenges for data generation. Developers must stay informed about emerging techniques, methodologies, and best practices, ensuring their datasets remain relevant and effective.
Adapting to new technologies requires ongoing training and a willingness to embrace change. Organizations should foster a culture of continuous learning, encouraging team members to attend workshops, conferences, and online courses focused on the latest developments in data generation and AI.
Ethical Considerations in Data Generation
As the use of image detection data becomes more prevalent, ethical considerations must be at the forefront of discussions surrounding its generation. Awareness and responsibility in handling data are paramount.
Privacy Concerns
Privacy concerns are paramount when generating image detection data. The collection and use of image data, especially those containing identifiable individuals, raise ethical dilemmas regarding consent and data ownership.
Developers should prioritize transparency in data sourcing, seeking explicit permission from individuals depicted in images whenever feasible. In instances where obtaining consent is impractical, opting for anonymization techniques can mitigate risks associated with privacy violations.
Furthermore, organizations must comply with legal frameworks governing data protection, such as GDPR in Europe and CCPA in California. Adhering to these regulations protects individuals’ rights and fosters trust between developers and society.
Addressing Algorithmic Bias
Algorithmic bias is another pressing ethical issue. If the datasets used to train models reflect societal biases, the resulting algorithms may perpetuate discrimination in real-world applications.
To counteract this issue, developers must actively seek out diverse datasets that encompass a broad range of perspectives and experiences. Continuous evaluation of model outputs through fairness audits helps identify potential biases, allowing for corrective actions to be taken.
Incorporating interdisciplinary teams that include ethicists and sociologists can also contribute to developing a more holistic approach towards ethical dilemmas stemming from image detection data generation.
Transparency and Accountability
Finally, ensuring transparency and accountability in data generation processes is essential. Developers should document the methodologies and sources used in creating datasets, allowing stakeholders to assess the validity and ethics of the data.
Creating open-source projects, publishing research findings, and engaging with communities can foster greater accountability within the field. Being transparent about challenges faced during data generation empowers others to learn from experiences, contributing to a shared knowledge base that enhances ethical practices across the industry.
Applications of Image Detection Data
The applications of generated image detection data span various sectors, each benefiting from enhanced AI capabilities. Recognizing these applications reveals the significance of high-quality data in driving innovation and improving lives.
Autonomous Vehicles
Autonomous vehicles represent one of the most exciting applications of image detection data. The ability to accurately detect objects, pedestrians, and road signs is critical for ensuring safe navigation in dynamic environments.
Image detection data is instrumental in training models to recognize various elements encountered on the road. With diverse datasets that include different terrains and weather conditions, autonomous vehicles can learn to adapt their behaviors accordingly, promoting safer travel experiences.
Healthcare Diagnostics
In the healthcare sector, image detection data has the potential to revolutionize diagnostics and patient care. Models trained on medical imaging data can assist radiologists in identifying anomalies, tumors, and other conditions with remarkable accuracy.
Generated data aids in training models capable of analyzing X-rays, MRIs, and CT scans. By providing medical professionals with advanced decision-support tools, image detection data can lead to timely interventions and improved patient outcomes.
Retail and Inventory Management
Retailers are increasingly leveraging image detection data for inventory management and customer experience enhancement. Image recognition systems can monitor stock levels on shelves, identify misplaced items, and analyze customer interactions to optimize store layouts.
By employing sophisticated image detection models, retailers can streamline operations and improve customer satisfaction. Ensuring that products are readily available and easy to locate ultimately leads to a more enjoyable shopping experience.
Security and Surveillance
Security and surveillance applications rely heavily on image detection data. From facial recognition systems to anomaly detection in surveillance footage, models trained on robust datasets play a vital role in enhancing safety and security measures.
In urban environments, smart surveillance systems equipped with image detection capabilities can assist law enforcement in monitoring public spaces while respecting privacy boundaries. Ethical considerations must guide the deployment of such technologies to ensure that they serve the public interest.
The Future of Image Detection Data Generation
As technology continues to evolve, so too does the landscape of image detection data generation. Several trends and innovations are shaping the future of this critical field.
Improved Automation Techniques
The future of image detection data generation is likely to witness continued advancements in automation techniques. Sophisticated algorithms will streamline the annotation process, enabling faster and more efficient data generation.
Leveraging machine learning techniques for semi-automated annotations can significantly reduce the manual workload, allowing developers to focus on improving model performance rather than spending excessive time on tedious tasks. As automation matures, we can expect higher fidelity datasets with minimal human intervention.
Integration of Augmented and Virtual Reality
The integration of augmented reality (AR) and virtual reality (VR) into data generation presents exciting possibilities. By simulating real-world environments, developers can create immersive datasets that mirror complex scenarios.
AR and VR technologies allow for dynamic interactions with objects, enabling the generation of diverse data capturing various aspects of object behavior and context. This approach paves the way for training highly adaptable models capable of navigating intricate environments seamlessly.
Collaborative Data Ecosystems
The future may also bring about collaborative data ecosystems where organizations share datasets for mutual benefit. By pooling resources, companies can create more extensive, diverse datasets that enhance model training while addressing challenges related to data scarcity and bias.
Establishing partnerships and data-sharing agreements fosters innovation and accelerates the development of robust AI systems. As data privacy and regulatory frameworks evolve, safe and ethical collaboration will become increasingly feasible.
Conclusion
Generating image detection data is a multifaceted endeavor that holds immense potential for advancing artificial intelligence applications across diverse fields. By prioritizing high-quality data, embracing innovative methods, and adhering to ethical considerations, organizations can build robust models poised to tackle real-world challenges. As technology continues to evolve, the future of image detection data generation promises exciting opportunities that will empower the next generation of intelligent systems. Staying informed and adaptable in this rapidly changing landscape will be crucial in unlocking the full potential of image detection data.
Looking to learn more? Dive into our related article for in-depth insights into the Best Tools For Image Generation. Plus, discover more in our latest blog post on transparent image generator. Keep exploring with us!
Related Tools:
Image Generation Tools
Video Generators
Productivity Tools
Design Generation Tools
Music Generation Tools